Authors: Xinlei Ren, Xiguang Zheng, Lianwu Chen, Chenglin Xu, Chen Zhang, Liang Guo, Bing Yu
Affiliation: Kuaishou Technology, Beijing, China
Abstract
Device coloration and room reverberation are two main factors that degrade the speech quality of user generated contents. Here, device coloration refers to the timbre difference between the original high-quality audio signal and the version captured by a low-quality recording hardware. The commonly used speech enhancement systems only remove the distortions introduced by noise and late reverberation signals, the device coloration and early reverberation distortions are untouched and the quality of enhanced speech is much lower than that of high-quality speech. In this paper, a neural network-based device decoloration and dereverberation system is proposed. This system directly estimates the original high-quality speech without any room or device related distortions, which has not been thoroughly investigated in the existing literature as far as we know. The results show that the proposed method achieves significant improvements than the baseline systems on various objective metrics and subjective MOS score. The robustness of proposed system could also be demonstrated on real recordings with unseen devices. Samples of restored speech clips can be found from https://xinleiren.github.io/interspeech2022/index.htmlSystem Architecture
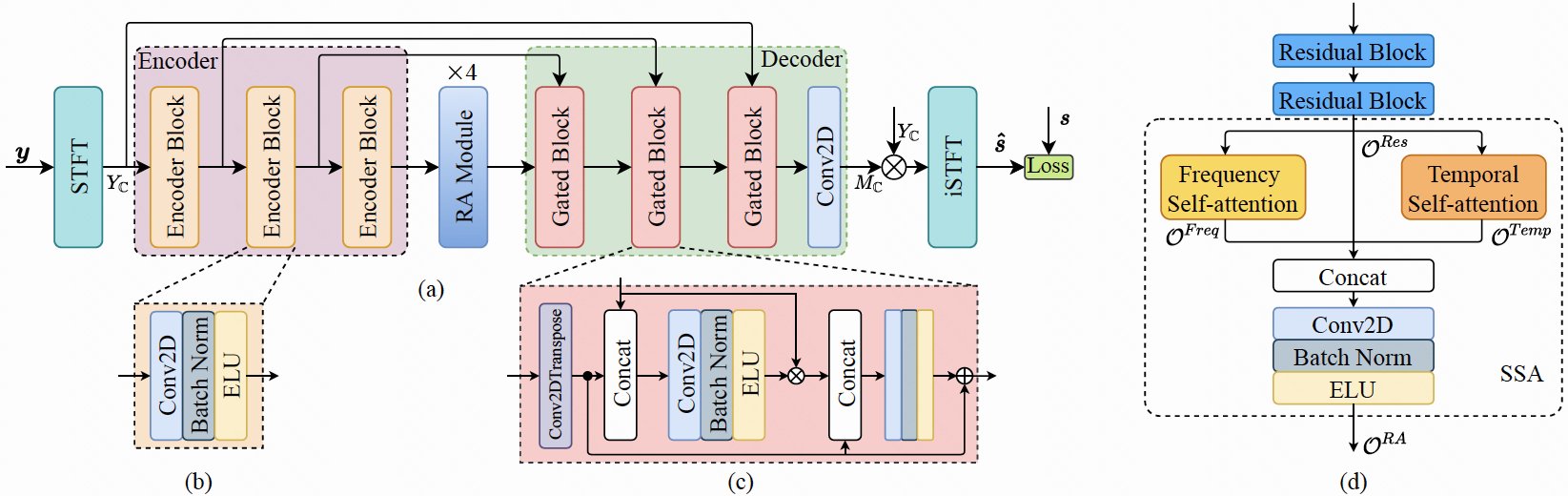
Demo
Part1: real recordings with reference
| reference | degraded | our approach restored | |
|---|---|---|---|
| sample1 |  |
 |
 |
| sample2 | 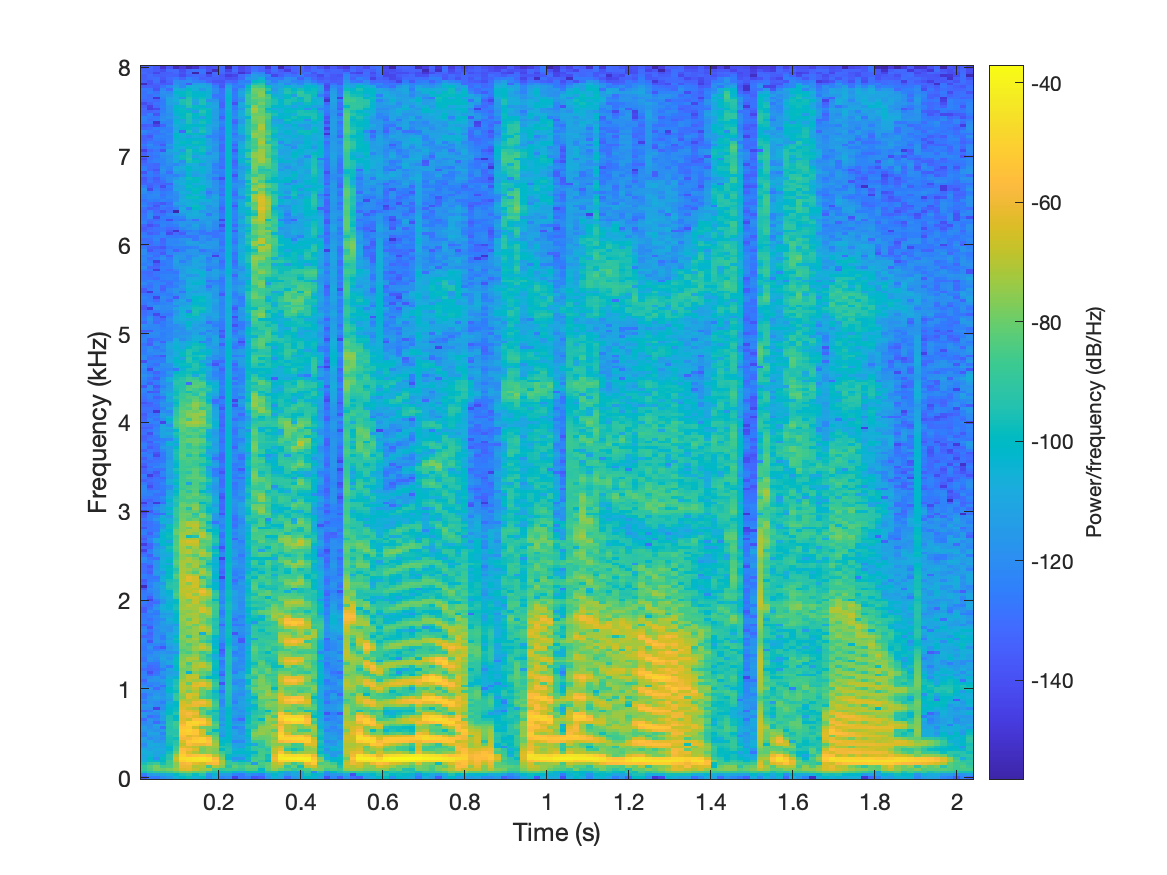 |
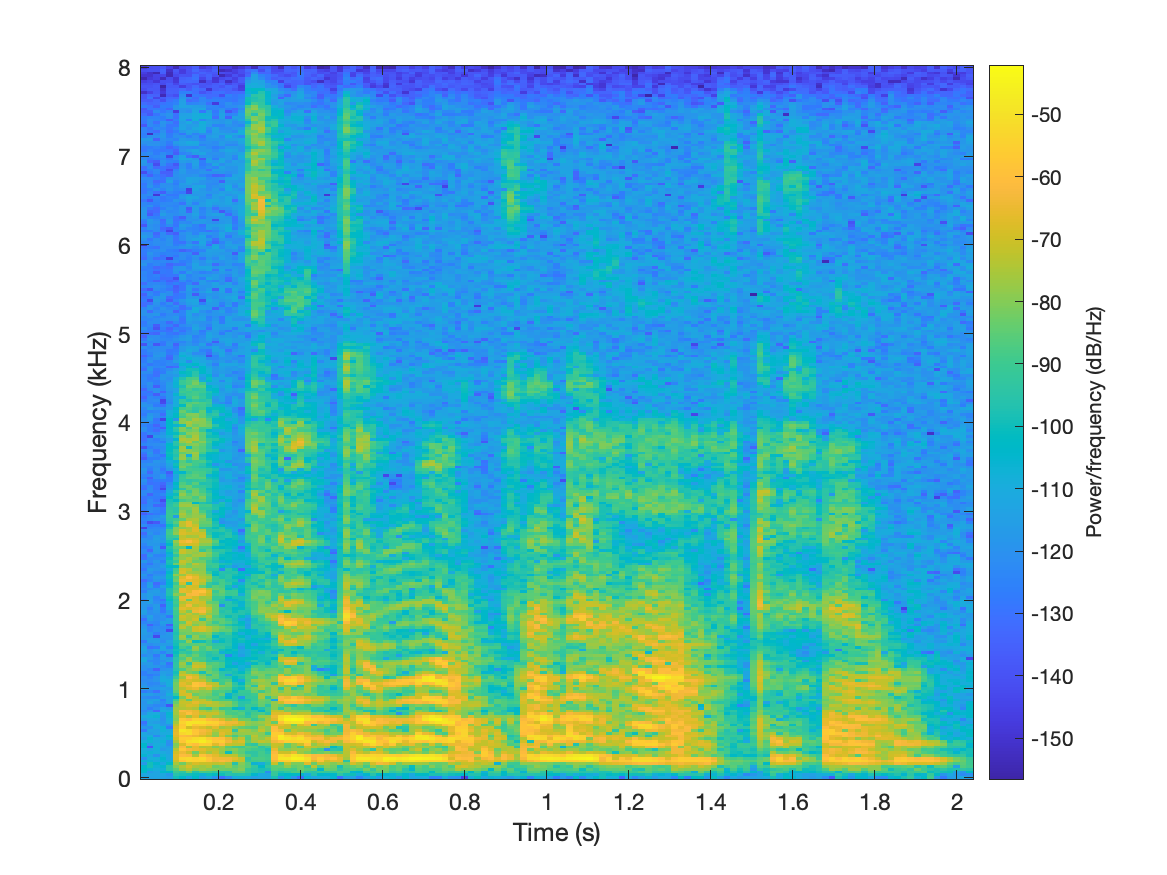 |
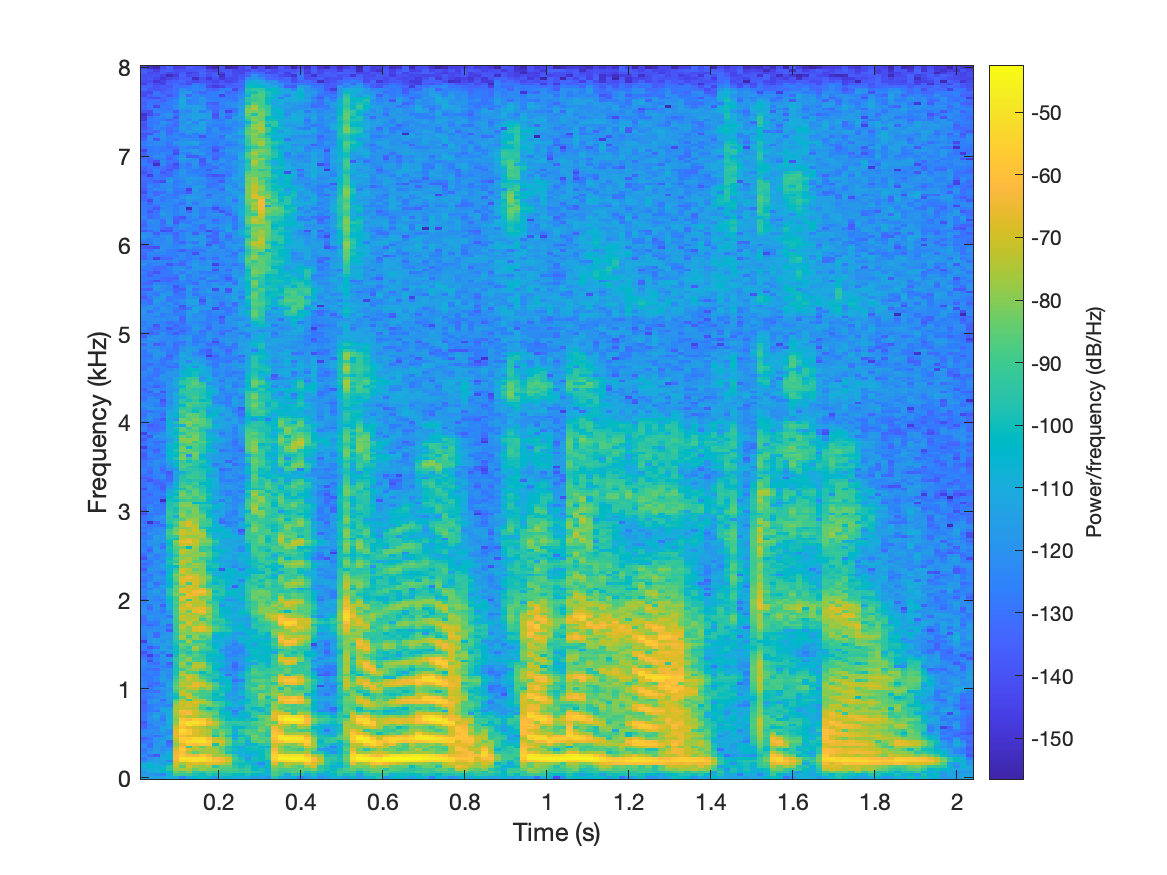 |
| sample3 |  |
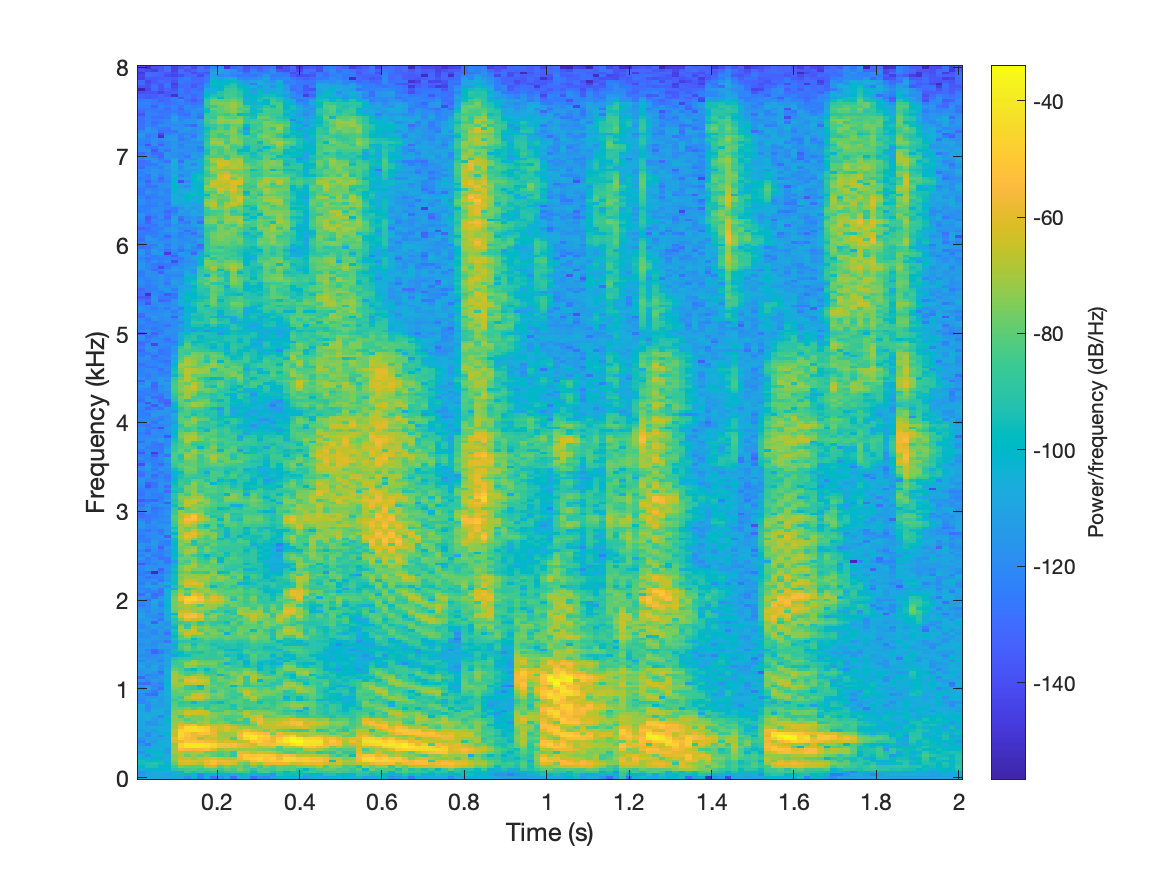 |
 |
| sample4 |  |
 |
 |
| sample5 | 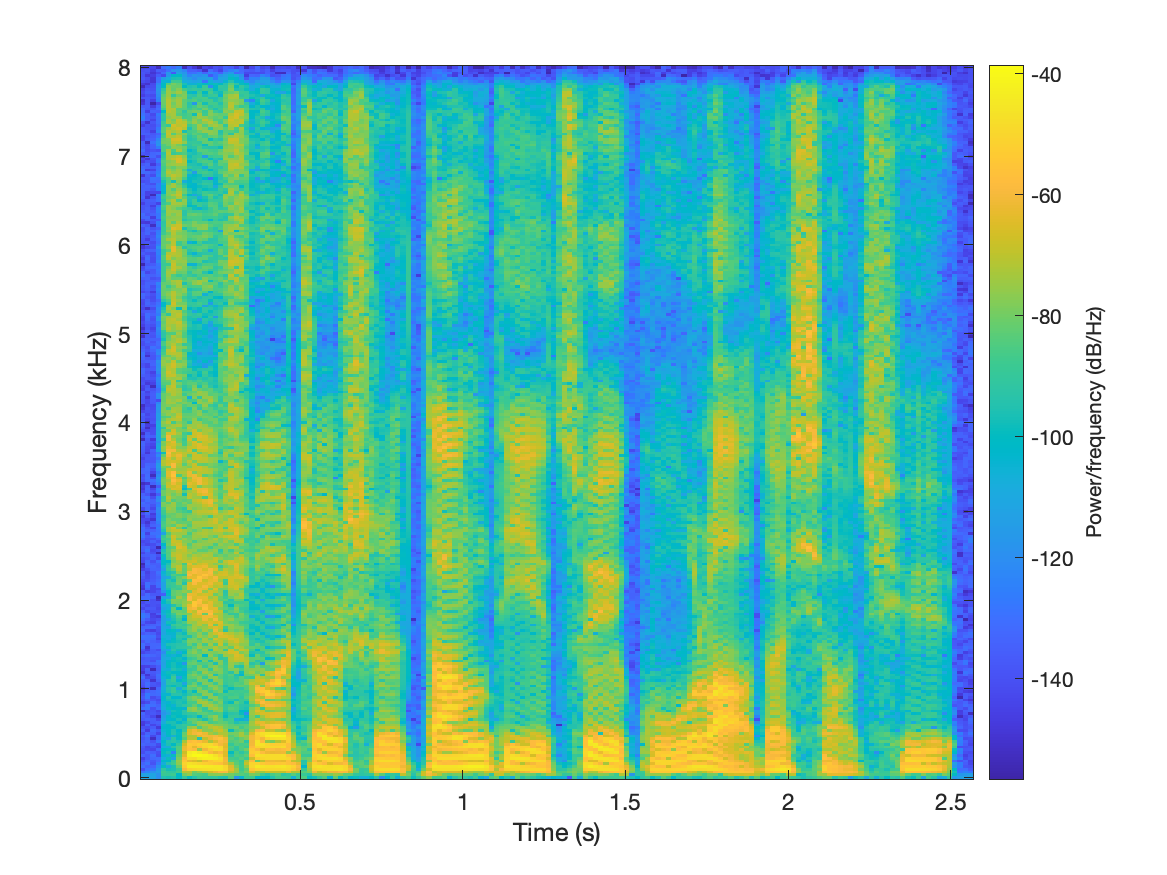 |
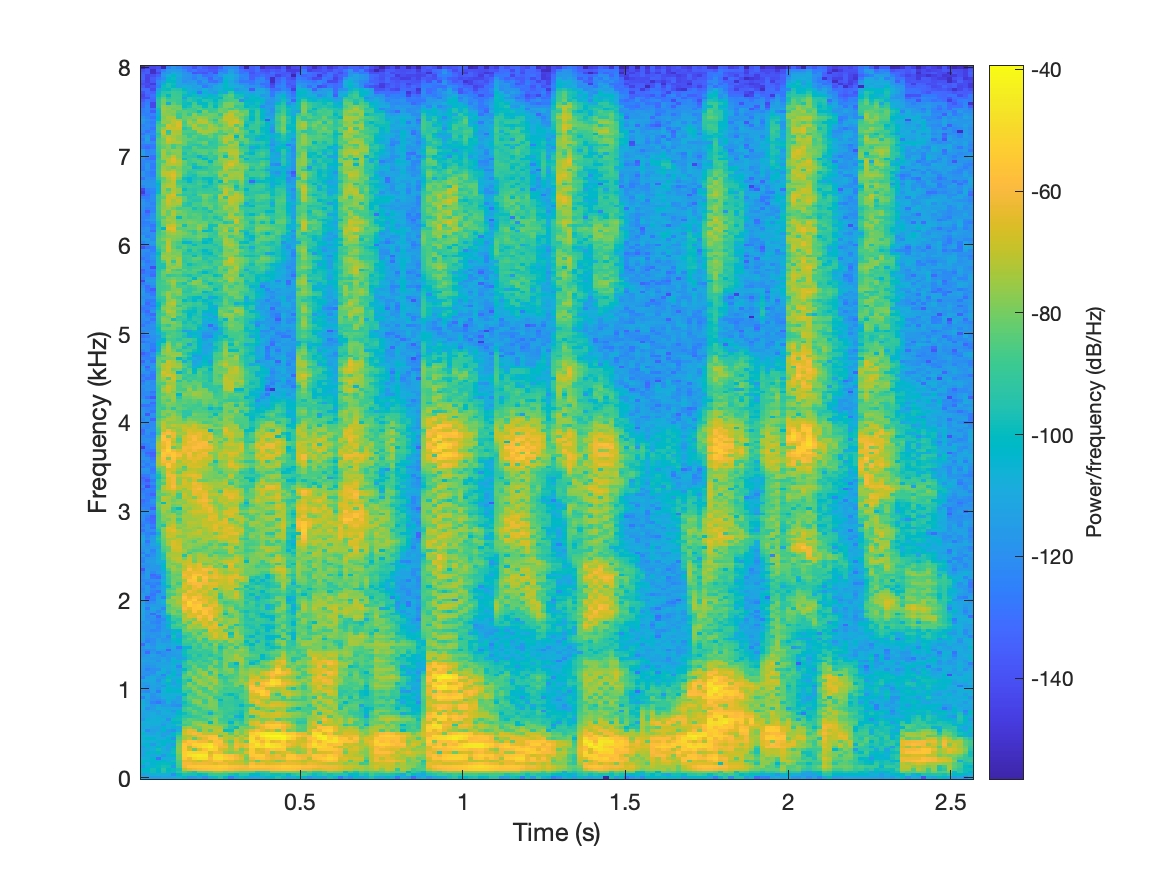 |
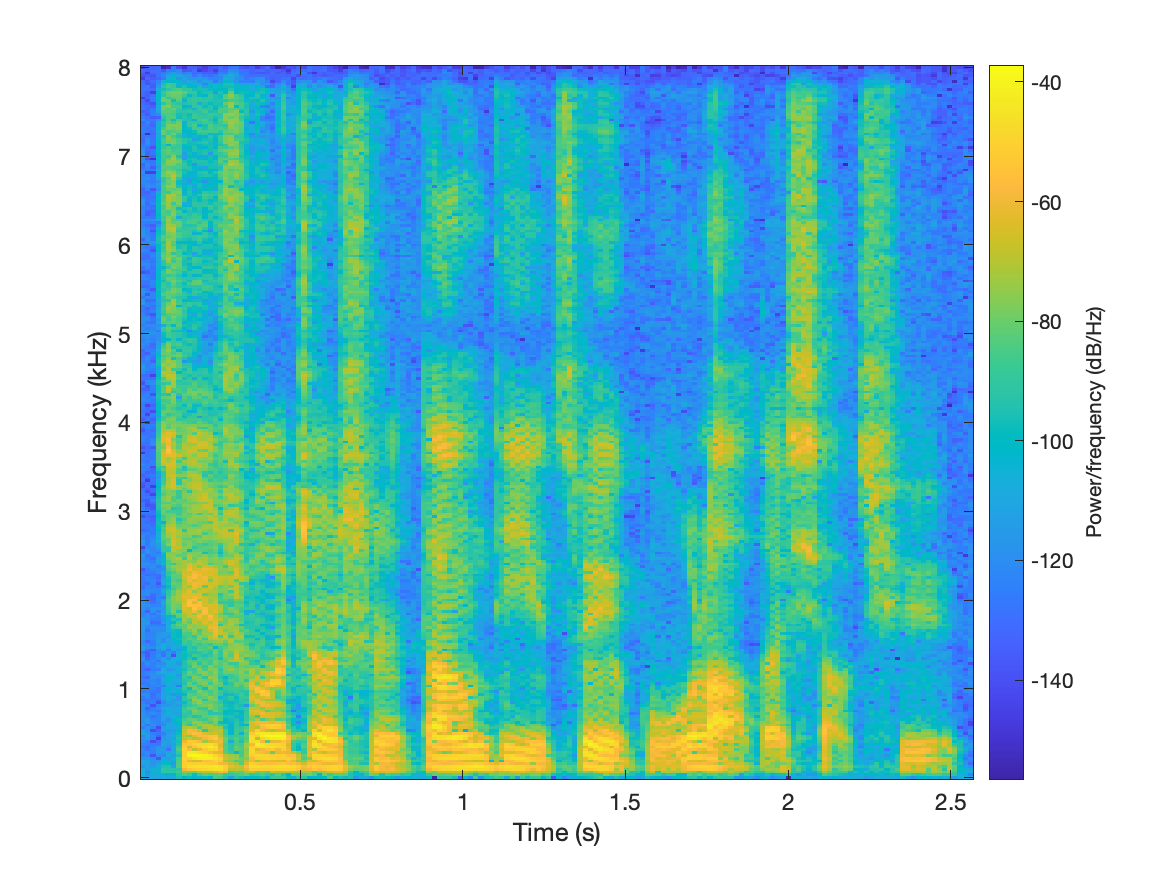 |
Part2: real recordings without reference
| degraded | our approach restored | |
|---|---|---|
| sample1 | 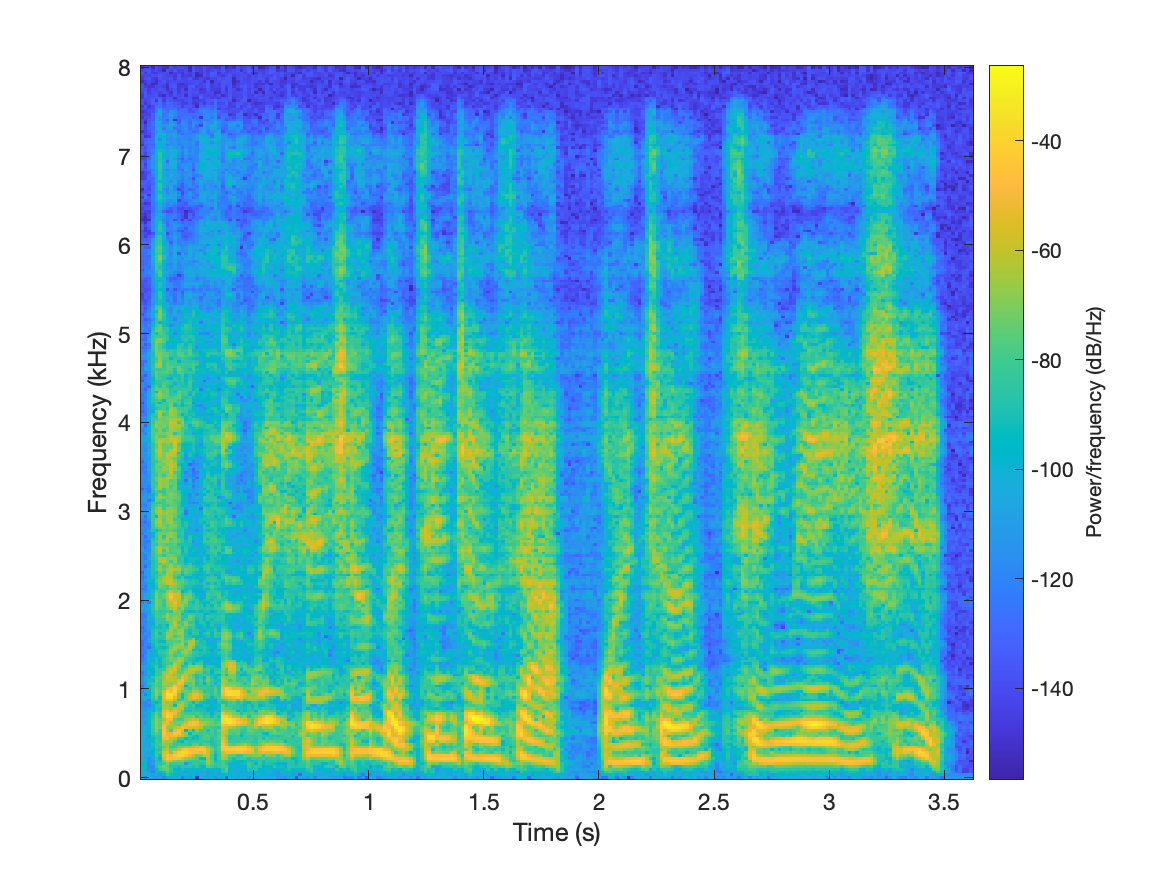 |
 |
| sample2 |  |
 |
| sample3 |  |
 |
| sample4 |  |
 |
| sample5 |  |
 |